
Disaster by Design/Safety by Intent #42
Disaster by Design
At 4:00 am on March 28, 1979, workers at the Three Mile Island (TMI) nuclear plant near Harrisburg, Pennsylvania were preparing to restart the Unit 1 reactor from a refueling outage. The Unit 2 reactor was marking its first anniversary—exactly one year earlier, a nuclear chain reaction had been achieved for the first time. A series of events over the next 135 minutes would end Unit 2’s life and delay Unit 1’s restart for several years.
Unit 2 was operating at 97% power when one of the two condensate pumps unexpectedly stopped running. The two feedwater pumps pulled more water from the piping than the single remaining condensate pump could supply. Automatic protective devices tripped both feedwater pumps. The loss of the feedwater pumps caused the water level in the steam generators as steam continued to exit them with little makeup water in return. Protective devices automatically tripped the main turbine and moments later triggered the rapid shut down of the reactor.
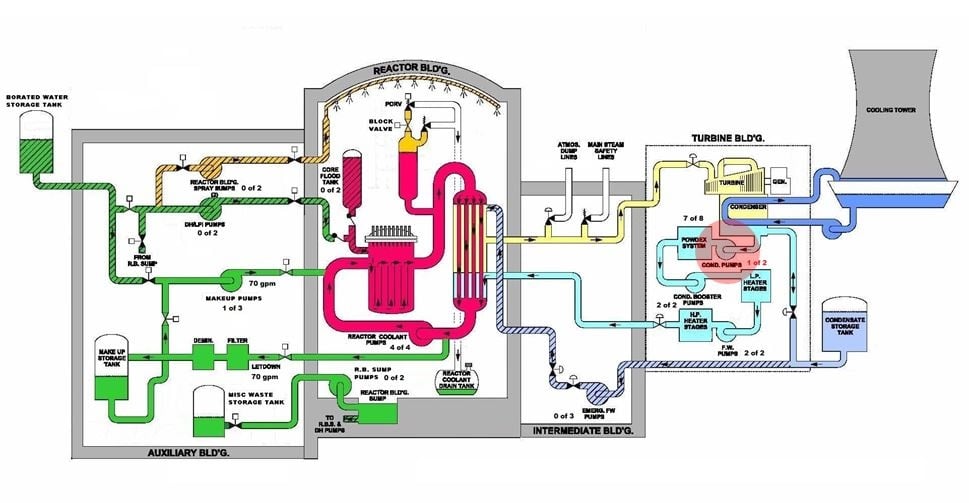
Fig. 1 (Source: Nuclear Regulatory Commission annotated by UCS)
It was not the first time the Unit 2 reactor had shut down due to problems in the feedwater system. In fact, the reactor had shut down twelve times for such problems. On December 2, 1978, alone it had shut down three times due to feedwater system problems. It would be the 13th time Unit 2 shut down due to feedwater system problems, and the last time for any reason.
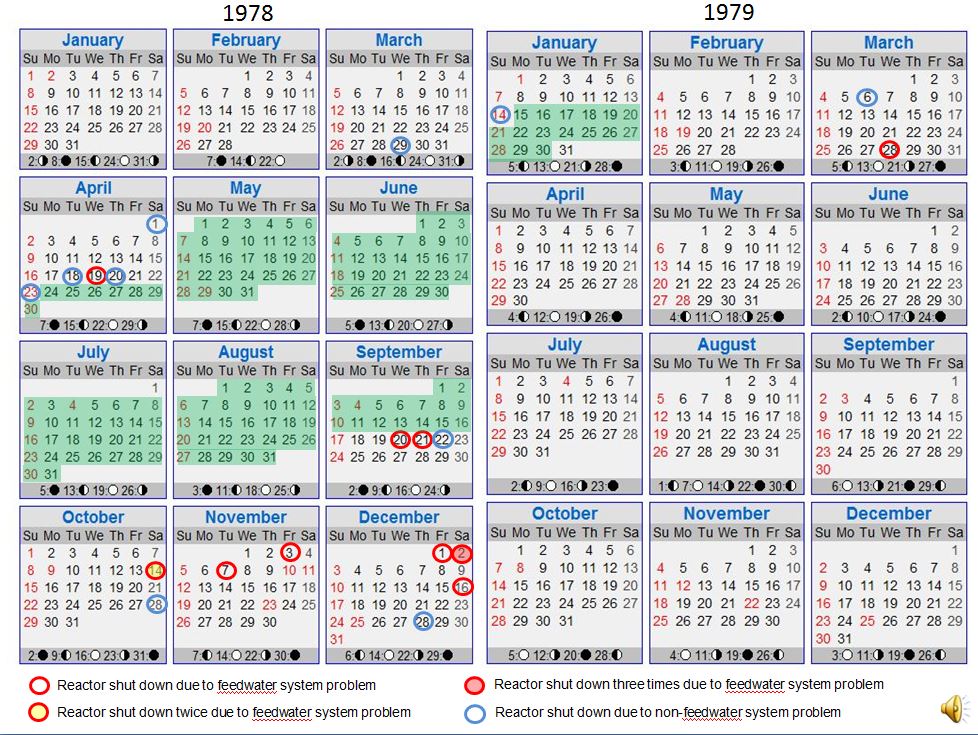
Fig. 2 (Source: UCS)
The steam generator is like a fulcrum between the energy produced by the reactor and the energy carried away by the steam. The transient resulting from the rapid shutdowns of the main turbine and reactor upset the energy balance. The imbalance caused the pressure of the water within the primary loop—the reactor vessel, the steam generators, the pressurizer, and the connecting piping—to increase. The power operated relief valve (PORV) on top of the pressurizer automatically opened to release steam to the reactor coolant drain tank inside the reactor building and curb the pressure rise.
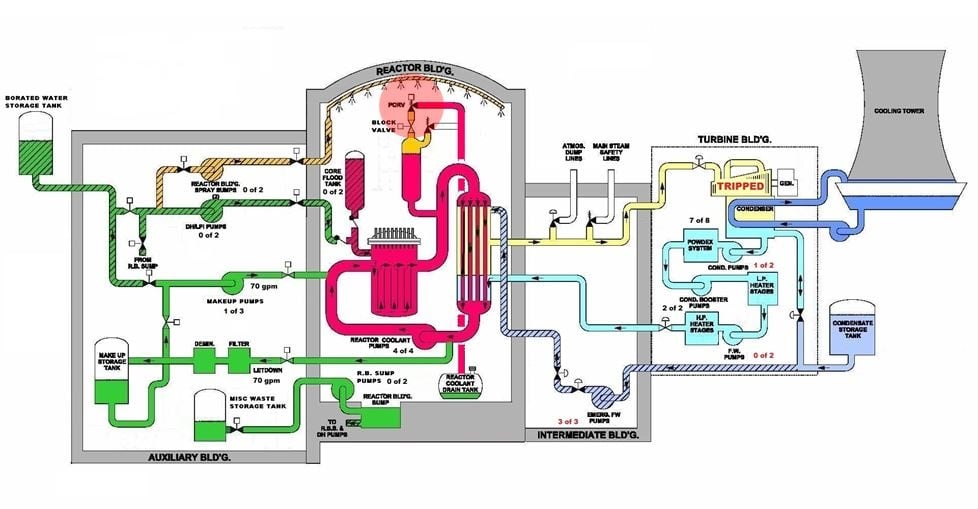
Fig. 3 (Source: Nuclear Regulatory Commission annotated by UCS)
The reactor’s design tried to restore the balance. The automatic shut down of the reactor reduced the energy production level from 97% to under 7%. And the emergency feedwater pumps automatically started for the purpose of restoring the flow of makeup water to the steam generators so the secondary loop could resume carrying away the energy being transferred from the primary loop.

Fig. 4 (Source: Nuclear Regulatory Commission)
But a few days earlier, the emergency feedwater system had been removed from service for testing. After completion of the tests, workers failed to re-open the valves between the emergency feedwater pumps and the steam generator. And tags applied to switches on the control room panel covered up the indicator lights showing that the valves were closed. So, the emergency feedwater pumps had started, but the closed valves prevented them from supplying makeup water to the steam generators. It took about eight minutes for the operators to detect this situation, open the valves, and restore makeup flow to the steam generators.
The secondary loop problem had been corrected, but a primary loop problem remained. The PORV had automatically opened to curb the pressure rise within the primary loop. The shut down of the reactor and the makeup flow to the steam generators restored the energy balance which resulted in primary loop’s pressure dropping back down towards, and then below, the normal value. The PORV was designed to automatically reclose as the primary loop pressure decreased. But the PORV failed to reclose and continued to discharged about 700 gallons per minute of primary loop coolant.
The open PORV caused monitoring instruments to show a falsely high water level inside the pressurizer. The pressurizer is a large metal tank partially filled with water. The pressurizer accommodates the expansion and contraction of water as it heats up and cools down. The pressurizer also allows the operators to control the pressure within the primary loop—electric coils in the bottom of the pressurizer can be turned on to warm the water and increase its pressure; nozzles in the top of the pressurizer can be used to spray cool water to lower the pressure.

Fig. 5 (Source: Nuclear Regulatory Commission annotated by UCS)
The operators’ training emphasized avoiding letting the pressurizer “go solid,” or become completely filled with water. The operators responded to the indication of high water level in the pressurizer by increasing the amount of letdown flow from the primary loop to storage tanks within the auxiliary building. They also turned off one of the makeup pumps in the auxiliary building that had automatically started. Their actions increased a mass imbalance in the primary loop—700 gallons per minute were exiting via the stuck-open PORV, more than 100 gallons per minute were leaving through the letdown line, and only 50 gallons per minute were being added by one of three makeup pumps. The primary loop was being drained of its cooling water at a rate of over 750 gallons per minute.
The operators fixated on the high water level problem in the pressurizer and discounted many warning signs of bigger problems caused by the drain down. The sustained flow through the stuck-open PORV filled the reactor coolant drain tank. About 15 minutes into the event, a relief valve automatically opened in response to the increasing pressure within the reactor coolant drain tank. But the flow into the tank was greater than the flow out the relief valve. The reactor coolant drain tank burst open. Coolant was draining from the primary loop and flooding the reactor building.
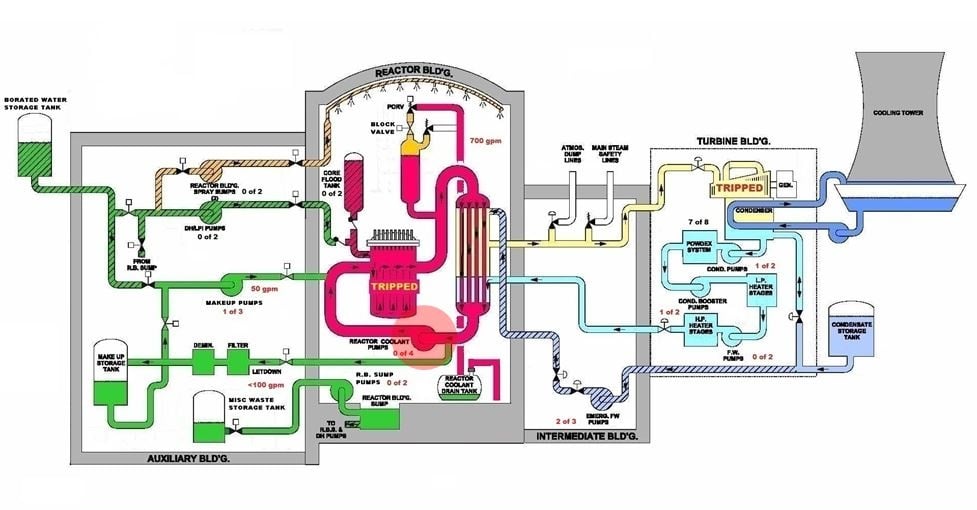
Fig. 6 (Source: Nuclear Regulatory Commission annotated by UCS)
About 25 minutes into the event, an operator observed that the temperature in the pipe between the PORV and the reactor coolant drain tank was abnormally high. But that reading was mistakenly attributed to the PORV’s “momentary” opening during the early moments of the event.
About 32 minutes into the event, thermocouples measuring the temperature of the water flowing out of the reactor core showed temperatures above the maximum range of 700°F. But the readings were mistakenly attributed to failed instruments.
About 38 minutes into the event, the operators turned off both of the reactor building sump pumps. The pumps had been running for nearly 30 minutes and the collection tanks in the auxiliary building were nearing full capacity. But the operators did not question where all this water in the reactor building was coming from.
(TMI is an acronym for Three Mile Island and, more recently, for Too Much Information. Ironically, the accident at TMI was caused not by TMI but by TLI—too little information.)
About 39 minutes into the event, instruments began showing the nuclear chain reaction rate steadily increasing. The operators did not mistakenly attribute this indication—they had no idea what it meant. The post-accident inquiry determined that the reduction of water inventory within the primary loop allowed more and more neutrons to reach the detectors mounted on the outside of the reactor vessel at the height of the reactor core.
About 40 minutes into the event, an operator observed that the temperature in the pipe between the PORV and the reactor coolant drain tank was still abnormally high. But that reading was again mistakenly attributed to the PORV’s “momentary” opening during the early moments of the event and not to the fact that it was still open.
About 45 minutes into the event, the radiation levels of the water flowing through the letdown line into the auxiliary building began increasing. Over the next 40 minutes, the radiation levels would increase ten-fold. The operators mistakenly attributed the radiation readings to “ultra-sensitivity” of the instruments.
About 73 minutes into the event, the operators turned off two of the four reactor coolant pumps. Indications for these large, electric motor powered pumps had been behaving erratically. For example, the amount of electrical current used by the pump motors, typically a steady value, began swinging high and low drastically. It was a sign that primary loop was emptying of water and that the pumps were no longer pushing solid water through the pipes, but the operators overlooked that warning sign.
About 80 minutes into the event, an operator observed that the temperature in the pipe between the PORV and the reactor coolant drain tank was still abnormally high. But that reading was again mistakenly attributed to the PORV’s “momentary” opening during the early moments of the event and not to the fact that it was still open.
About 101 minutes into the event, the operators turned off the remaining two reactor coolant pumps. Vibration levels indicated that the pumps were shaking so badly they risked tearing themselves apart. But the operators continued to focus on the “high” water level inside the pressurizer caused by the stuck-open PORV they believed to have re-closed.
About 114 minutes into the event, thermocouples in the hot leg piping between the reactor vessel and the steam generators began indicating abnormally high valves. The operators did not understand what these high temperatures meant. The post-accident inquiry determined that as the reactor vessel emptied of water, decay heat from the reactor core superheated steam. Superheated steam rather than hot water flowed from the reactor vessel to the steam generators.

Fig. 7 (Source: Nuclear Regulatory Commission)
About 134 minutes into the event, radiation detectors in the reactor building trended rising levels, eventually going off the scale.
About 139 minutes into the event, an operator arriving for the dayshift watch closed a manual valve in the pipe between the stuck-open PORV and the blown open reactor coolant drain tank.
It had taken about two hours to drain enough water from the primary loop to uncover the upper portion of the reactor core. That’s all it had taken to overheat and damage the exposed nuclear fuel. Some of the overheated fuel flowed like molten lava to pool in the reactor vessel’s lower dome. Enough of it wandered away from where it was supposed to be that Unit 2 never generated another watt of electricity. A not-so-happy birthday, indeed.
Safety by Intent
If it’s true that one learns from mistakes, the Three Mile Island accident allowed the nuclear industry and the NRC to take several steps towards genius. The steps included:
- Correcting design problems such as the automatic closure of valves on pipes passing through the containment wall and the indicating ranges for instruments monitoring radiation levels.
- Improving human/machine interfaces and operating procedures.
- Enhancing emergency preparedness, including requirements for plants to immediately notify NRC of significant events and creating an NRC Operations Center staffed 24 hours a day. Drills and response plans are now tested by plant owners several times a year while state and local agencies participate in drills once every two years evaluated by the Federal Emergency Management Agency and the NRC.
- Integrating NRC observations, findings, and conclusions about licensee performance and management effectiveness into a periodic, public report (initially called Systematic Assessment of Licensee Performance or SALP reports, now reflected in the quarterly evaluations per the Reactor Oversight Process).
- Expanding the NRC’s resident inspector program—first authorized in 1977— to station at least two NRC inspectors at each operating U.S. nuclear plant.
- Establishing the Institute of Nuclear Power Operations, the industry’s own “policing” group, and formation of what is now the Nuclear Energy Institute to provide a unified industry approach to generic nuclear regulatory issues, and interaction with NRC and other government agencies.
- Enacting programs for collecting, assessing, and sharing relevant data so operating experience can be used to prevent recurrences of safety problems.
Perhaps most valuable among the lessons from the TMI accident involved the extensive overhauling of training programs for control room operators and other nuclear plant workers. The operators made many mistakes at TMI that day. But their performance reflects on the poor standards of training at the time rather than on their individual capabilities. Individuals typically train for 18 months before getting certified as control room operators and then spend several weeks each year in training sustaining their proficiencies. Not only is more time devoted to training, but the quality of the training itself has improved substantially. Full-scale control room simulators complement classroom instruction, allowing workers to apply their skills in virtual environments.
TMI also illustrates what I term the “short list approach to nuclear safety.”
The list above is but a brief abridged listing of many steps taken after TMI to prevent the next nuclear disaster. The longer the list, the less excuse the nuclear industry and the NRC have for not having undertaken at least some of those steps before disaster compels them to be taken. For example, the NRC assigned inspectors full-time at some nuclear plants beginning in 1977. After TMI, the NRC expanded this program by assigning full-time inspectors to all operating nuclear plants. If it was a swell idea to post NRC inspectors at some plants, it was a bad idea not to have NRC inspectors at all plants.
To be sure, each nuclear disaster will reveal lessons that can reduce vulnerabilities in the future. A short list of lessons strongly suggests that the nuclear industry and the NRC had taken reasonable measures to avert disaster. The longer the list, the lower the nuclear safety IQ.
—–
UCS’s Disaster by Design/ Safety by Intent series of blog posts is intended to help readers understand how a seemingly unrelated assortment of minor problems can coalesce to cause disaster and how effective defense-in-depth can lessen both the number of pre-existing problems and the chances they team up.